由于学业要求,我需要查阅大量的文言文词汇。于是我便趁此机会,练习使用 Python 爬虫实现大规模的查询操作。
声明:本文仅供学习参考用途,希望大家体贴对方,不要使用大批量爬虫导致网站卡顿
网站分析
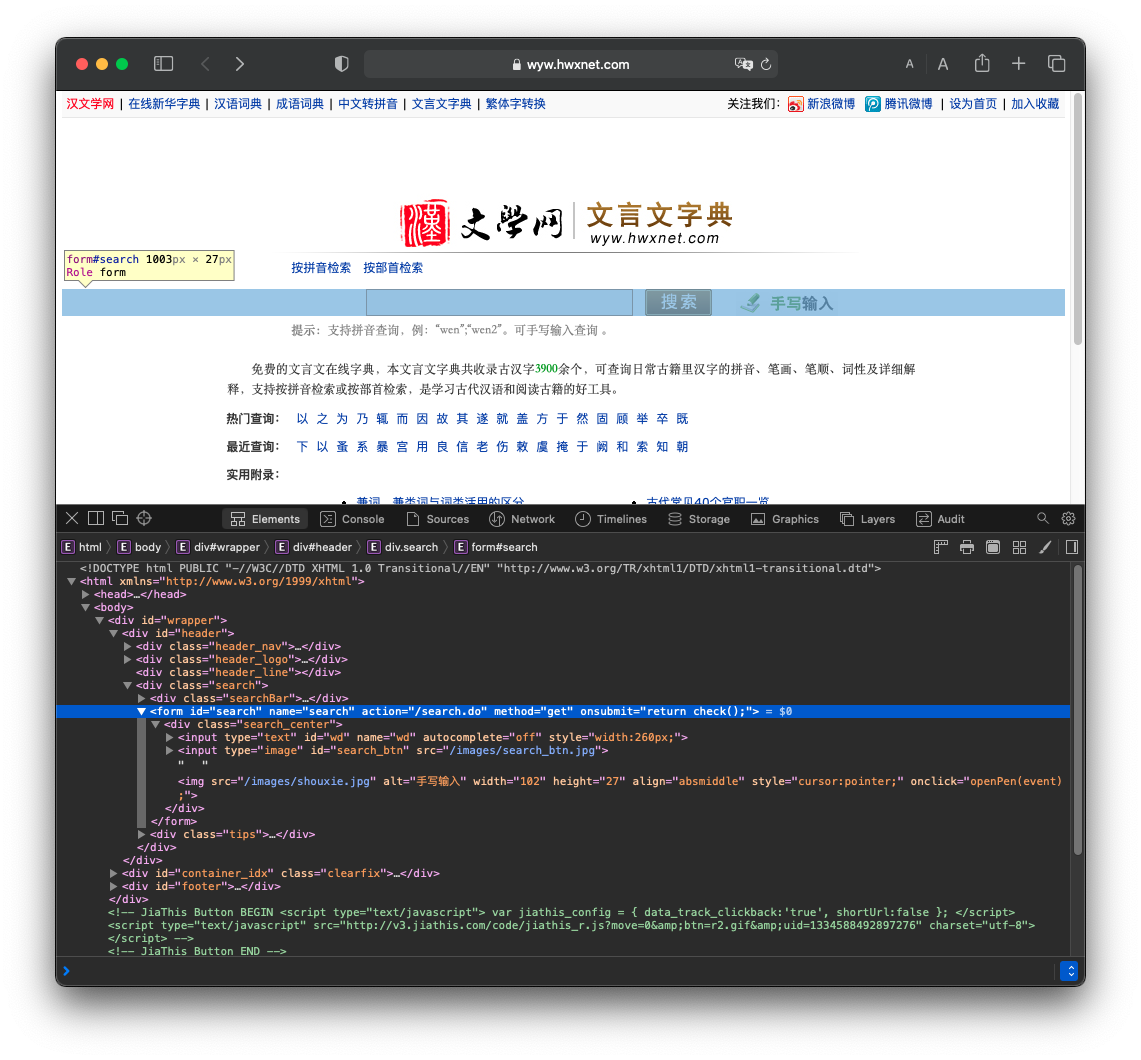
首先可以看出,该搜索框使用了一个 form 标签,其中wd参数是要搜索的内容。
这种形式很大程度上方便了我们后续的查询操作,我们只需要自己拼接字段发送GET请求即可得到结果页面。
但是我们又发现搜索结果有两种不同的形式:一种是直接单字的解释,另一种是多个字的解释。那我们就需要对不同情况分别处理。
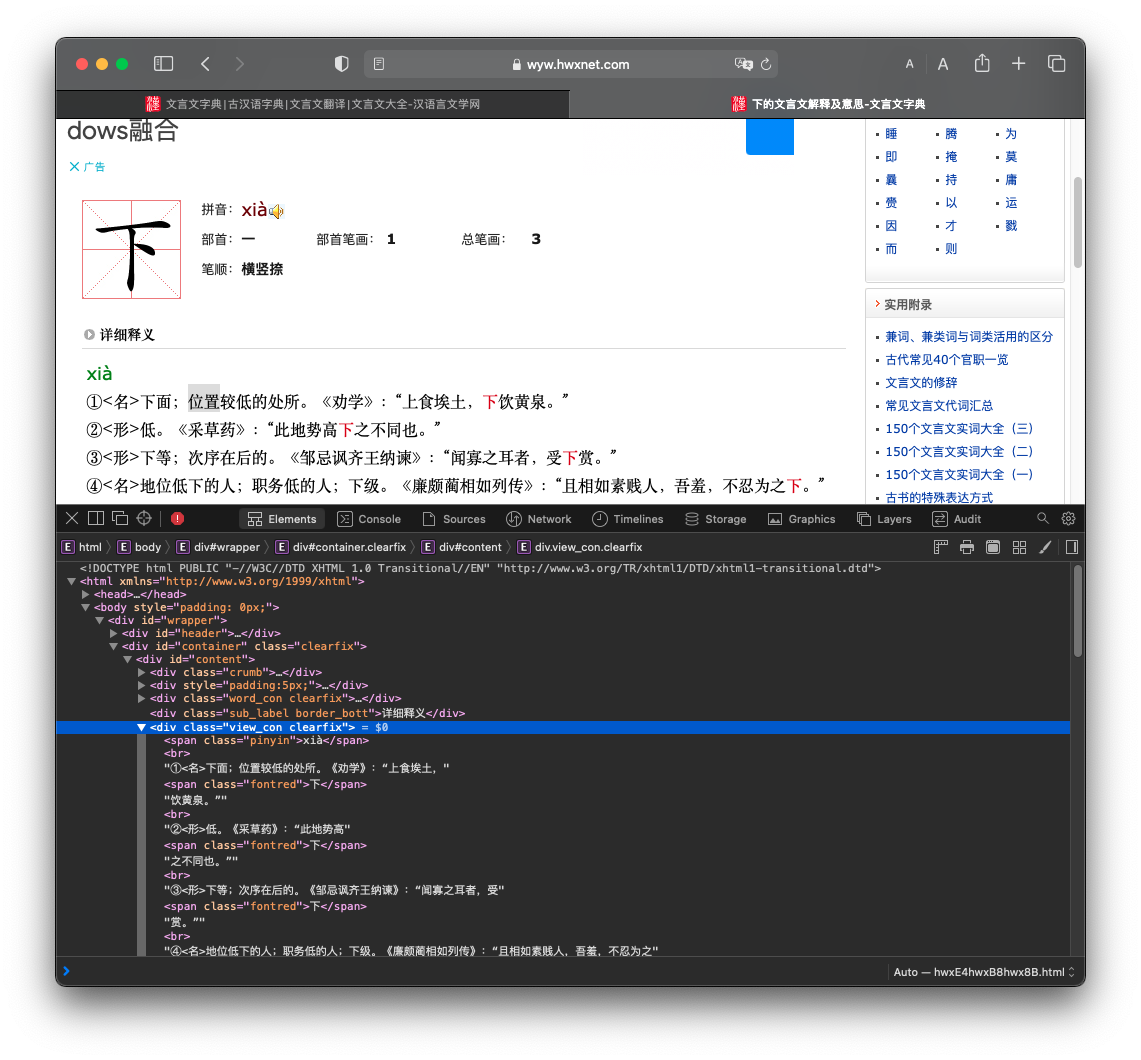
首先对于这种单字的搜索结果,我们只需要提取这个div中的搜索结果即可。
final_result = soup.find('div', class_="view_con clearfix")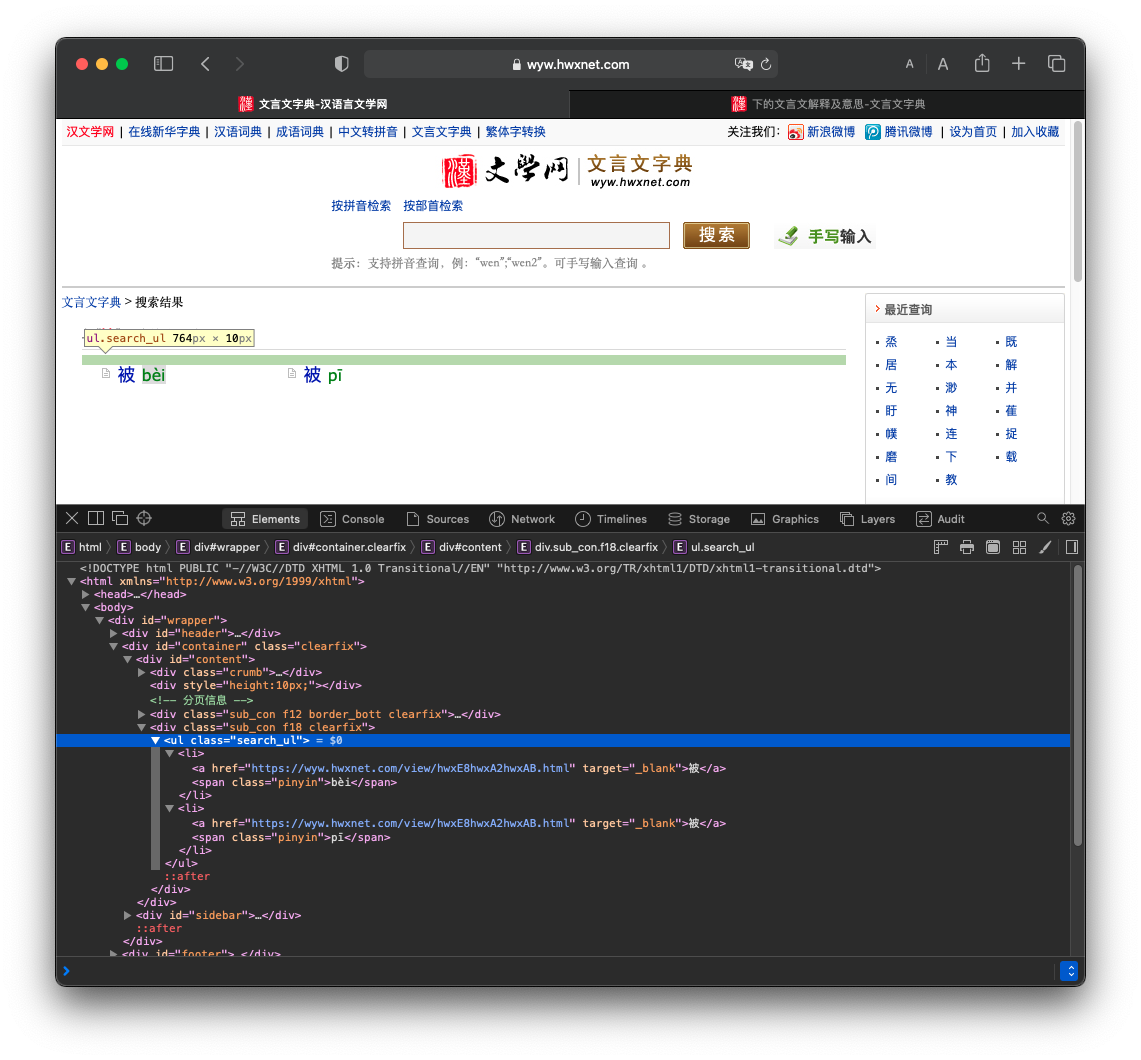
然后对于这种多个汉字的搜索结果,我们只需要提取其中的一个链接再打开。
(因为我们的字都是唯一确定的,所以最后打开的页面内容都是完全一样的。同时因为确定每个字都能找到,异常处理其实也可以省掉,但实际上还是有必要的。)
#拿到其中一个子页面的链接
s_url = soup.find('ul', class_="search_ul").find('a').get('href')
#打开字页面,以下同上
s_result = requests.get(s_url)
s_soup = BeautifulSoup(s_result.content, 'html.parser')
final_result = s_soup.find('div', class_="view_con clearfix")这样我们就能实现所有查询操作了。
代码编写
我们先使用一个字符串储存待查询的字,然后依次读取。由于字符串中含有空格,需要小小处理一下。
search_target = """
白 表 第 反 奉 废 伏 姑 躬 怀 号 径 加 觉 旧
激 极 据 略 论 敛 谋 内 难 遣 趋 起 饶 夙 收
市 岁 署 事 矢 输 深 脱 听 通 谓 衔 雅 遇 援
寓 御 有 缘 言 状 征 止 张 著 自 主 字 至 遂
作 足 伯 临 迁 效 许 益 云 业 退 肆 迫 强 简
"""
search_target = search_target.replace("n","")
search_target = search_target.replace(" ","")然后我们开始查询,遍历字符串里的所有汉字。
先GET查询结果,然后根据结果分析是否为单字。从而得到最终结果。
result_markdown = ""
for target in search_target:
print("Now searching for", target)
#首先获得搜索结果
search_result = requests.get(
"https://wyw.hwxnet.com/search.do?wd={}&x=8&y=7".format(target))
soup = BeautifulSoup(search_result.content, 'html.parser')
#根据结果分析是否为单字
if soup.find('ul', class_="search_ul") is None:
#如果是单字,直接得到结果
final_result = soup.find('div', class_="view_con clearfix")
else:
#如果是多字,先获取子页面链接
s_url = soup.find('ul', class_="search_ul").find('a').get('href')
#打开子页面,得到结果
s_result = requests.get(s_url)
s_soup = BeautifulSoup(s_result.content, 'html.parser')
final_result = s_soup.find('div', class_="view_con clearfix")
result_markdown += "## {}n{}n".format(target,
md.handle(str(final_result)))
sleep(1) #让它搜索的慢一点,减轻网站压力,做有责任的好程序员最后只需要格式化一下,写到文件里就行了。这样就可以更好看。
result_markdown=result_markdown.replace("<","`")
result_markdown=result_markdown.replace(">","`")
result_markdown=result_markdown.replace("《","**《")
result_markdown=result_markdown.replace("》","》**")
fileName='result.md'
with open(fileName,'a') as file:
file.write(result_markdown)最终代码
其实这里还是有一点小问题,就是一旦过程中哪个词没有查到或者过程出现了什么问题,会直接退出,这样什么结果都得不到。所以如果想要实现更佳的性能还是最好加上异常捕捉和处理部分。但是由于我是自己用,就不用这么多麻烦事了。
from time import sleep
from bs4 import BeautifulSoup
import requests
import html2text
search_target = """
白 表 第 反 奉 废 伏 姑 躬 怀 号 径 加 觉 旧
激 极 据 略 论 敛 谋 内 难 遣 趋 起 饶 夙 收
市 岁 署 事 矢 输 深 脱 听 通 谓 衔 雅 遇 援
寓 御 有 缘 言 状 征 止 张 著 自 主 字 至 遂
作 足 伯 临 迁 效 许 益 云 业 退 肆 迫 强 简
"""
"""
按 拔 拜 报 暴 备 比 币 辟 薄 裁 操 策 差 长
陈 称 出 处 传 垂 次 存 错 贷 德 独 多 夺 发
伐 方 分 奉 赋 干 苟 购 果 会 计 将 矜 景 竟
居 课 理 名 命 逆 披 趣 让 稍 舍 身 审 师 释
视 疏 图 委 闻 文 务 息 系 向 延 夷 意 引 游
责 直 置 志 中
"""
"""
爱安被倍本鄙兵病察朝曾乘
诚除辞从殆当道得度非复负
盖故顾固归国过何恨胡患或
疾及即既假间见解就举绝堪
克类怜弥莫乃内期奇迁请穷
去劝却如若善少涉胜识使是
适书孰属数率说私素汤涕徒
亡王望恶微悉相谢信兴行幸
修徐许阳要宜遗贻易阴右再
造知致质治诸贼族卒走左坐
"""
search_target = search_target.replace("n","")
search_target = search_target.replace(" ","")
md = html2text.HTML2Text()
result_markdown = ""
for target in search_target:
print("Now searching for", target)
search_result = requests.get(
"https://wyw.hwxnet.com/search.do?wd={}&x=8&y=7".format(target))
soup = BeautifulSoup(search_result.content, 'html.parser')
if soup.find('ul', class_="search_ul") is None:
final_result = soup.find('div', class_="view_con clearfix")
else:
s_url = soup.find('ul', class_="search_ul").find('a').get('href')
s_result = requests.get(s_url)
s_soup = BeautifulSoup(s_result.content, 'html.parser')
final_result = s_soup.find('div', class_="view_con clearfix")
# print(final_result)
# print(md.handle(str(final_result)))
result_markdown += "## {}n{}n".format(target,
md.handle(str(final_result)))
sleep(1)
#print(result_markdown)
result_markdown=result_markdown.replace("<","`")
result_markdown=result_markdown.replace(">","`")
result_markdown=result_markdown.replace("《","**《")
result_markdown=result_markdown.replace("》","》**")
fileName='result.md'
with open(fileName,'a') as file:
file.write(result_markdown)